You rewrote the system prompt. You swapped from Gemini 2.5 to Sonnet 4.6. The agent feels faster, maybe a little sharper. So you ship it. Two days later, your support queue fills up. Turns out the new version handles edge cases worse. You just ran an uncontrolled experiment on your users.
AI agents are non-deterministic. The same input can produce different outputs across runs. A prompt tweak that improves one category of requests might break another. Unlike traditional software, you can't write unit tests that cover every possible interaction. What you need is a way to try changes on real traffic, measure the impact, and decide based on data.
That's what A/B testing does. Connic now lets you run controlled experiments on your agents. Split traffic between the current version and a variant, compare cost, latency, success rate, and quality scores side by side, then pick the winner with confidence.
Why A/B Test Your Agents
Every change to an AI agent is a hypothesis. "This prompt will be more accurate." "This model will be cheaper without losing quality." "This new tool will speed up responses." A/B testing turns hypotheses into experiments with measurable outcomes.
Built-in A/B testing routes traffic between agent versions and scores the results, with no separate experimentation tool to wire up.
Try Connic freeHow It Works
The concept is simple. You have a base agent (the control), and you create a variant with the change you want to test. Connic routes a percentage of live traffic to the variant, while the rest continues going to the control. Both versions run in parallel on real requests, and every run is tracked and attributed to its group.
Variant agents are regular agent configurations. They can change anything: the model, the system prompt, the tools, the temperature. A naming convention keeps it obvious which agent is the base and which is the variant:
order-processor.yaml # base agent (control)
order-processor-test-faster-model.yaml # variant: testing a cheaper model
order-processor-test-new-prompt.yaml # variant: testing a rewritten promptDeploy both alongside each other. The variant sits dormant until you create a test and start routing traffic to it.
What You Can Test
Since variants are full agent configurations, the experiments you can run are wide open.
name: order-processor-test-faster-model
model: gemini/gemini-2.5-flash # cheaper, faster model
description: "Processes incoming customer orders"
system_prompt: |
You process incoming orders...
tools:
- orders.process
- inventory.checkEverything else stays the same. The variant inherits the exact same workflow. The only difference is the variable you're testing.
Running a Test
Setting up a test takes less than a minute once your variant is deployed.
- 1.Deploy your variant. Push the variant YAML alongside your base agent. After deployment, it shows up as an available test variant.
- 2.Open the base agent and click Manage A/B Tests in the header.
- 3.Create a new test. Pick the variant, set the traffic percentage, and configure a minimum sample size.
- 4.Start the test. Tests begin in Draft status so you can review the configuration before going live.
- 5.Monitor and conclude. Watch the comparison metrics fill in as runs come through. When you have enough data, conclude the test and declare a winner.
Reading the Results
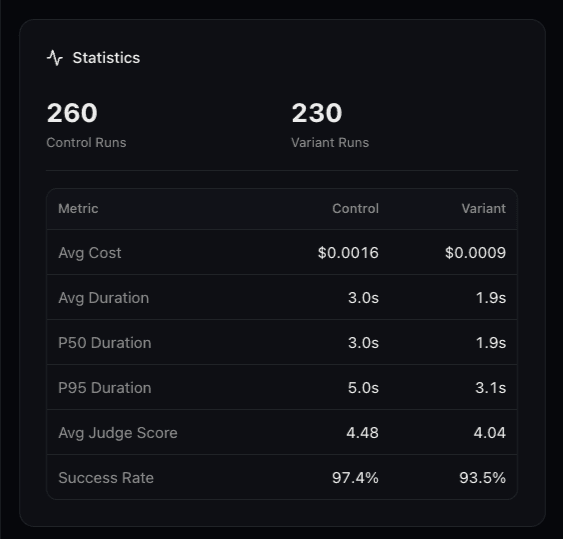
The test detail view gives you a side-by-side comparison across every metric that matters:
Every run in your history shows a variant badge so you can quickly spot which requests went to which version. Filter the runs table by variant name to drill into specific results.
Auto-Rollback: The Safety Net
Experiments shouldn't break production. When you enable auto-rollback, Connic watches the variant's failure rate within a rolling window of recent runs. If it crosses your configured threshold, the test pauses and traffic stops going to the variant.
When a rollback triggers, all traffic immediately returns to the control agent. The test stays paused with a clear error message explaining what happened, so you can investigate, fix the variant, and try again.
Pair It with Judges
A/B testing tells you which version is better. Judges tell you why. When you configure a judge on the base agent, it automatically evaluates both control and variant runs. The average judge score shows up in your A/B test comparison, giving you a quality signal alongside cost and latency. This is automated agent scoring doing the grading, so the comparison reflects output quality, not just whether a run succeeded.
Sticky Sessions
If your agents handle multi-turn conversations, you don't want a user bouncing between the control and variant mid-session. When sessions are configured, Connic keeps the same user on the same version for the entire conversation. If the test ends or pauses, sessions fall back to the base agent.
Practical Scenarios
A few experiments that work well in practice:
Best Practices
Getting Started
Ready to stop guessing? Here's how to run your first experiment:
- 1.Pick one thing you want to test: a different model, a new prompt, or an updated tool
- 2.Create the variant agent YAML with the change and deploy it alongside the base
- 3.Open the base agent, click Manage A/B Tests, and create a test with 10% traffic
- 4.Enable auto-rollback, set a minimum sample size of 100, and start the test
- 5.Wait for data, compare the results, and ship the winner
No more "deploy and pray," no more reverting changes because something feels off. Let real traffic tell you which version is better.
For the complete setup guide, check the A/B Testing documentation. New to Connic? Start with the quickstart guide to deploy your first agent, then come back here and run your first experiment.