You changed a prompt, swapped a model, or refactored a tool. Did anything break? With traditional code, your test suite gives you an answer in seconds. With AI agents, most teams ship a change, watch the dashboard, and hope for the best. That's not engineering. That's gambling against a non-deterministic system.
Today we're spotlighting Connic Tests, a testing framework built specifically for the way agents actually behave. It treats non-determinism as a first-class citizen, lets you assert on the entire trace (not just the final string), and becomes the gate between a green commit and a production deploy.
Why Agents Break Traditional Test Frameworks
Pytest, Jest, JUnit. They all assume the same input always produces the same output. That assumption is the foundation of every assertion you've ever written. Agents shred that assumption. The same prompt can return different tokens, take different tool paths, or surface a flaky failure that disappears on retry. Test suites that pretend the output is deterministic end up either useless (passing every red build) or unusable (failing every green one).
Failure modes ordinary test frameworks miss:
Connic Tests was designed around exactly these problems.
Write assertions against real agent runs and catch regressions before they reach production.
Get started freeThe 30-Second Tour
A test suite is just a YAML file at tests/<agent-name>.yaml. Same flat layout as middleware/, no scaffolding, no boilerplate. Each file declares one or more test cases for the agent of the same name.
version: "1.0"
agent: stress-tester # optional, defaults to the filename stem
defaults:
runs: 10 # invoke the agent 10 times per case
success_threshold: 90 # 9 out of 10 must pass
timeout_s: 60
tests:
- name: returns_id_10
payload: '{"a": 4, "b": 6}'
expected_result: output.id == 10
expected_tool_calls:
- math.calculator.add # called at least once
- math.calculator.add: invocations >= 5 # ...or with an expression
expected_no_tool_calls:
- email.send # must NOT be calledThat's a complete, production-ready test. Ten invocations, a 90% pass threshold, an output assertion, two positive tool-call expectations, and a forbidden side effect. No fixtures, no runners, no glue code. Just the behavior you care about.
Built for Non-Determinism
The first thing that makes Connic Tests feel different is runs and success_threshold. Together they let you encode statistical expectations directly in the test contract.
runs: 1) or a regression sentinel (runs: 50, success_threshold: 95). Tune per case so cheap cases stay cheap and critical cases get statistical rigor. Every individual invocation is recorded with its agent run ID and pass/fail outcome, so a case that fails on 3 of 50 runs takes you straight to the three offending traces. No log spelunking required.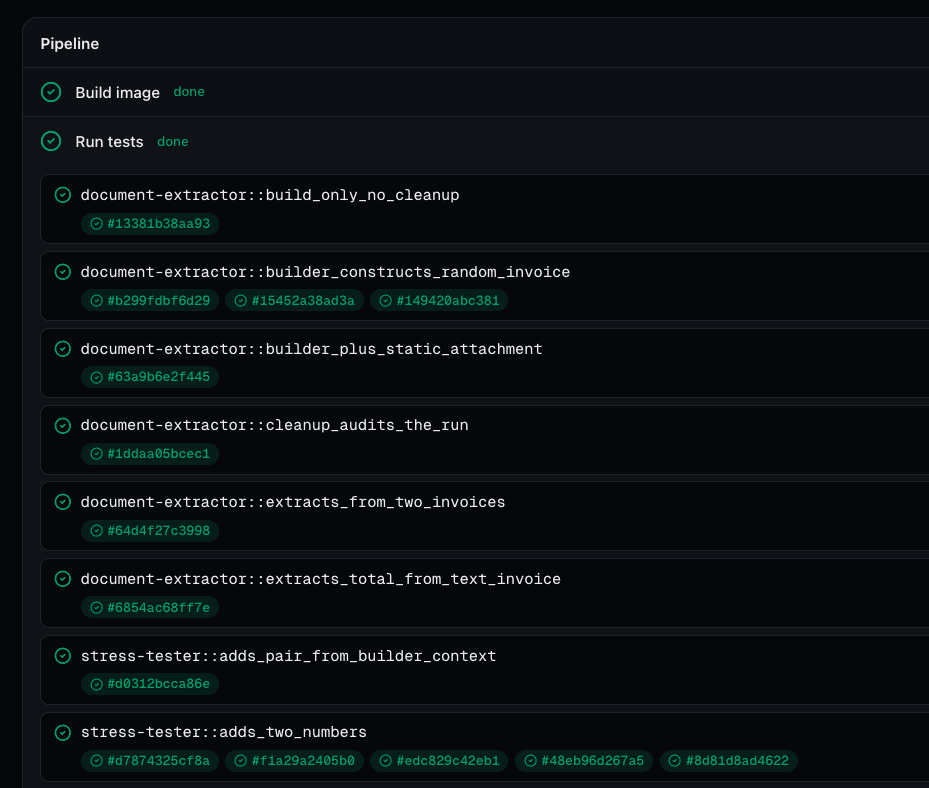
Assertions That Match How Agents Actually Work
A string-equality check on the agent's final output is almost never the assertion you want. Connic Tests gives you four assertion shapes, and each one is an expression, not a hardcoded comparator.
output, error, and status. Write output.total > 0, output.status == "refunded", or any other safe expression. JSON payloads are parsed automatically.math.calculator.add: invocations >= 5 asserts on the call count. Catches the silent regression where an agent stops using a tool you depend on.expected_result, the run still has to reach the completed status to pass. A free, baseline “did it crash?” check on every case.assertEquals, assertContains) cap the questions you can ask. Expressions don't. Anything you can compute over the output object (numeric comparisons, length checks, nested keys, set membership) is already a valid assertion. Same engine that powers Connic's trace filters, evaluated safely server-side.Multimodal Fixtures Without the Setup
Half of the agents people deploy today read PDFs, parse invoices, OCR receipts, or describe images. Their tests should too. Drop a binary in tests/files/ and reference it by name. The runner base64-encodes it and delivers a multimodal payload to the agent.
tests:
- name: extract_invoice_total
payload: "Extract the total amount from this invoice."
files:
- invoice_a.pdf
- invoice_b.pdf
runs: 5
success_threshold: 100
expected_result: output.total > 0 and output.currency == "EUR"Five runs, each receiving both PDFs alongside the prompt, with a strict expectation that every single one returns a positive Euro total. No mocking. No stubs. Real model calls against real fixtures.
Dynamic Builders for Stateful Tests
Some tests can't be static. To test a refund agent properly, you have to create a real charge first. To test an updater, you have to seed a real row. Dynamic builders are small Python modules in tests/builders/ that produce the test payload at run time and tear down the fixture afterwards.
import stripe
def build(context, builder_args, test_name, payload, files):
"""Create a real Stripe charge, then ask the agent to refund it."""
charge = stripe.Charge.create(
amount=builder_args["amount_cents"],
currency="usd",
source="tok_visa",
)
# stash state for cleanup() to read back
context["charge_id"] = charge.id
return f"Please refund charge {charge.id} for the customer."
def cleanup(run, context, builder_args):
"""Runs after the agent finishes (pass OR fail)."""
charge_id = context.get("charge_id")
if charge_id:
# ensure the fixture is gone even if the agent forgot
try:
stripe.Refund.create(charge=charge_id)
except stripe.error.InvalidRequestError:
pass # already refunded by the agent under test
return None # returning False would mark the case failedtests:
- name: refunds_a_real_charge
builder: create_charge_then_refund
builder_args:
amount_cents: 4200
expected_result: output.status == "refunded"
expected_tool_calls:
- stripe.refund.create
expected_no_tool_calls:
- email.sendThe builder creates state, the agent operates on it, the assertion verifies behavior, and the cleanup hook tears down the fixture, even if the test failed. Builders run inside the same sandbox as your agent, so they see the same environment, the same secrets, and the same tools.
False from cleanup() additionally fails the case. Useful when teardown itself reveals a bug (e.g. you discover the agent didn't actually refund the charge it claimed to). Every other return value is treated as success.Mock the Tools, Keep the Reasoning
Builders are how you test against real state. Mocks are the opposite move: exercise the agent's reasoning without letting its tools actually run. No row written, no email sent, no third-party charge. Drop a Python module in tests/mocks/ exposing hierarchical mock_* functions and point a case at it with the mocks field.
# Each function stands in for one or more custom file tools. The
# signature is always mock(tool_name, params, context) -> result,
# and the return value is substituted as the tool result.
# Exact tool: tools/data/customer.py :: add_customer
def mock_data_customer_add_customer(tool_name, params, context):
return {"id": "cust_test_1", "name": params.get("name")}
# Everything else under tools/data/
def mock_data(tool_name, params, context):
return {"ok": True}tests:
- name: adds_a_customer_without_touching_the_db
payload: '{"name": "Ada"}'
mocks: customer_mocks
strict_mocks: true
# The add_customer call is served by the mock but still recorded,
# so the assertion holds while nothing ever reaches a real datastore.
expected_tool_calls:
- data.customer.add_customer: params.name == "Ada"
expected_result: output.id == "cust_test_1"For every custom file tool the agent calls, the runner picks the most specific mock you defined, from the exact function (mock_data_customer_add_customer), to its module (mock_data_customer), to its namespace (mock_data), to a catch-all mock. Predefined tools and api: tools always run for real; only your own file tools get swapped.
expected_tool_calls and expected_no_tool_calls keep asserting on what the agent reached for, while the value you hand back stands in as the result.strict_mocks: true (per file or per case) and the run fails the moment the agent calls a tool you didn't mock. “Isolate the agent” becomes a hard contract: every tool it touches must be one you accounted for.Tests Are a Deployment Gate, Not a Vibe Check
Tests that run on a developer's laptop and nowhere else are a comfort, not a control. Connic Tests is wired directly into the deployment pipeline:
During every deployment, Connic discovers the test suites in your project, expands each case according to its runs count, and executes them in an isolated runner that mirrors the production environment. Same tools, same secrets, same model providers. If any case fails its threshold, the deployment stops. Production never sees the broken build.
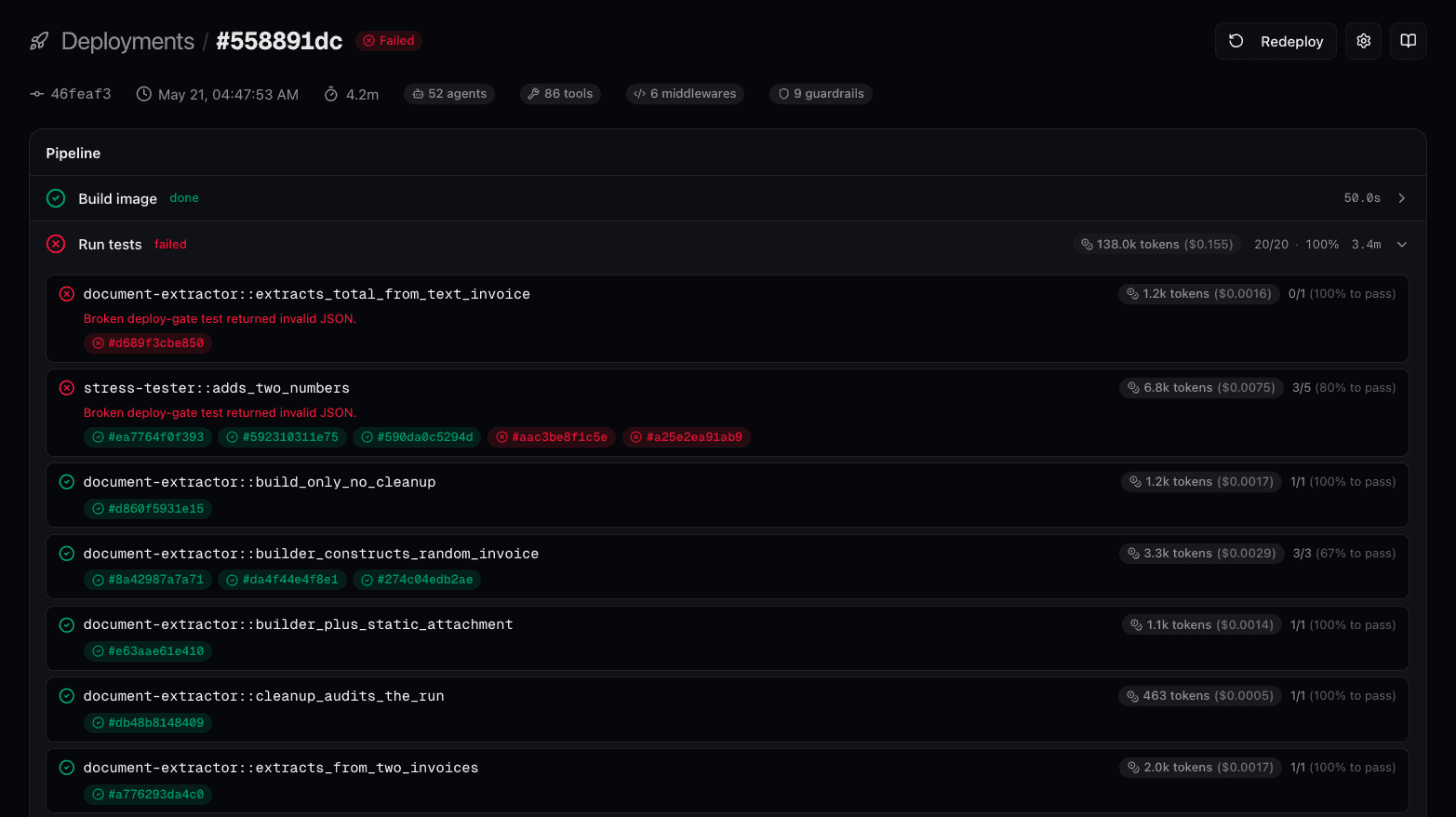
connic test executes the same framework against your current environment and streams results back to your terminal.Real-World Patterns
expected_tool_calls: warehouse.query: invocations >= 1 to every test case. Future model swaps that re-introduce the bug fail the deployment automatically.expected_no_tool_calls: email.send. A regression that adds an “helpful” confirmation email is caught at deploy time, not in a customer complaint.How It Fits the Rest of the Platform
Connic Tests is the deterministic, pre-production gate. It sits alongside two other quality systems on the platform:
| System | When It Runs | What It Answers |
|---|---|---|
| Connic Tests | During deployment | Does this build pass the contract I wrote? |
| LLM Judges | After every (or sampled) production run | How is quality trending against my rubric? |
| A/B Testing | Across two live variants | Which version performs better on real traffic? |
Tests catch regressions before they ship. Judges score the runs that do ship. A/B testing decides between two versions that both passed. Use all three and you have a proper feedback loop instead of a hope-driven release process.
Getting Started
Adding tests to an existing agent is a five-minute exercise:
- 1.Create a
tests/directory in your project root, next toagents/ - 2.Add
tests/<agent-name>.yamlwith one or two cases. Start withruns: 1for fast feedback - 3.Run
connic testlocally and watch the cases stream in - 4.Push and deploy. The same suite now gates production. Crank
runsup on the cases that matter most
For the full schema reference (every field, every default, every expression binding) see the Testing documentation. New to Connic? Start with the quickstart guide to deploy your first agent, then come back here and gate it with a test that fails before your customers do.